A review of binary classification models, metrics used to evaluate them, and performing the metric calculations with Ibis.
We’re going explore common classification metrics such as accuracy, precision, recall, and F1 score, demonstrating how to compute each one using Ibis. In this example, we’ll use DuckDB, the default Ibis backend, but we could use this same code to execute against another backend such as Postgres or Snowflake. This capability is useful as it offers an easy and performant way to evaluate model performance without extracting data from the source system.
Classification models
In machine learning, classification entails categorizing data into different groups. Binary classification, which is what we’ll be covering in this post, specifically involves sorting data into only two distinct groups. For example, a model could differentiate between whether or not an email is spam.
Model evaluation
It’s important to validate the performance of the model to ensure it makes correct predictions consistently and doesn’t only perform well on the data it was trained on. These metrics help us understand not just the errors the model makes, but also the types of errors. For example, we might want to know if the model is more likely to predict a positive outcome when the actual outcome is negative.
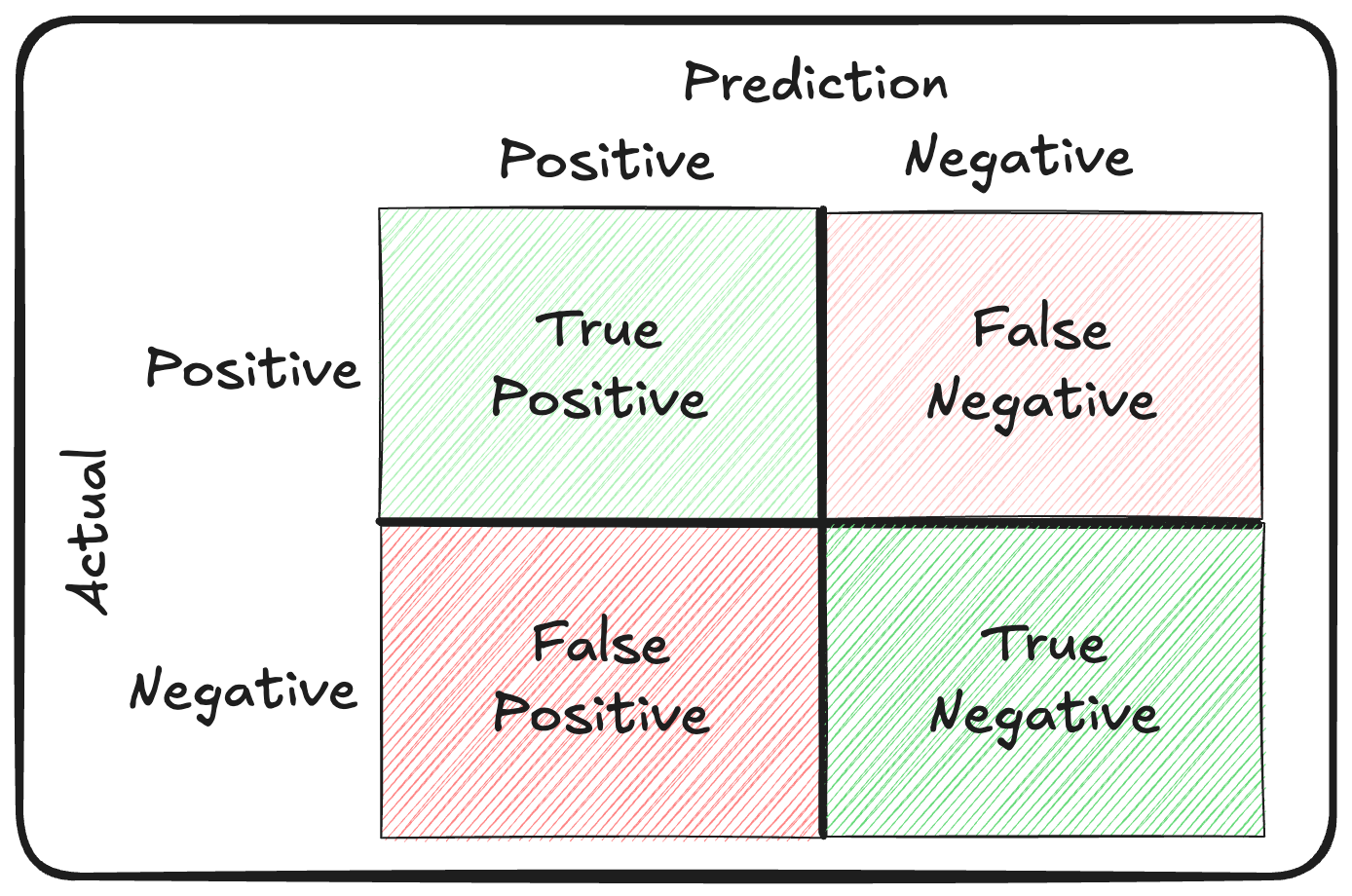
The easiest way to breakdown how this works is to look at a confusion matrix.
Confusion matrix
A confusion matrix is a table used to describe the performance of a classification model on a set of data for which the true values are known. As binary classification only involves two categories, the confusion matrix is a simple 2x2 table where each cell shows the count of true positives, false positives, false negatives, and true negatives.
Here’s a breakdown of the terms with examples.
True Positives (TP)
Correctly predicted positive examples.
We guessed it was a spam email, and it was. This email is going straight to the junk folder.
False Positives (FP)
Incorrectly predicted as positive.
We guessed it was a spam email, but it actually wasn’t. Hopefully, the recipient doesn’t miss anything important as this email is going to the junk folder.
False Negatives (FN)
Incorrectly predicted as negative.
We didn’t guess it was a spam email, but it really was. Hopefully, the recipient doesn’t click any links!
True Negatives (TN)
Correctly predicted negative examples.
We guessed it was not a spam email, and it actually was not. The recipient can read this email as intended.
Building a confusion matrix
Sample dataset
Let’s create a sample dataset that includes twelve rows with two columns: actual and prediction. The actual column contains the true values, and the prediction column contains the model’s predictions.
To create the confusion matrix, we’ll group by the outcome, count the occurrences, and use pivot_wider. Widening our data makes it possible to perform column-wise operations on the table expression for metric calculations.
cm = ( t.group_by("outcome") .agg(counted=_.count()) .pivot_wider(names_from="outcome", values_from="counted"))cm
Now that we’ve built a confusion matrix, we’re able to more easily calculate a few common classification metrics.
Metrics
Here are the metrics we’ll calculate as well as a brief description of each.
Accuracy
The proportion of correct predictions out of all predictions made. This measures the overall effectiveness of the model across all classes.
Precision
The proportion of true positive predictions out of all positive predictions made. This tells us how many of the predicted positives were actually correct.
Recall
The proportion of true positive predictions out of all actual positive examples. This measures how well the model identifies all actual positives.
F1 Score
A metric that combines precision and recall into a single score by taking their weighted average. This balances the trade-off between precision and recall, making it especially useful for imbalanced datasets.
We can calculate these metrics using the columns from the confusion matrix we created earlier.
By pushing the computation down to the backend, the performance is as powerful as the backend we’re connected to. This capability allows us to easily scale to different backends without modifying any code.
We hope you give this a try and let us know how it goes. If you have any questions or feedback, please reach out to us on GitHub or Zulip.